 |
OpenStudioCore:project |
|
OpenStudioCore:project |
The OpenStudio ProjectDatabase stores energy simulation project data for projects with less than 10,000 models. In addition, the ProjectDatabase is a basic serialization format for a number of OpenStudio classes, and allows for fast query of high-level information about files and data points stored as attributes and tags. The ProjectDatabase is saved to the OSP (OpenStudio Project) file format, which is a SQLite database. The ProjectDatabase stores all of its data in objects that derive from class Record. ProjectDatabase and all Records are implemented using the pointer to implementation (pImpl) idiom, so normal copy semantics result in wrapper objects sharing pointers to the same implementation object.
Each Record object represents a single row in a ProjectDatabase table. The two important classes deriving directly from Record are ObjectRecord, which stores information about a single object, and JoinRecord, which records a relationship between two ObjectRecords . The ProjectDatabase uses single table inheritance with a single table for each specialization directly below ObjectRecord or JoinRecord. For example, DiscreteVariableRecord and ContinuousVariableRecord both derive from VariableRecord, which derives from ObjectRecord. So DiscreteVariableRecords and ContinuousVariableRecords (which is further specialized into ModelRulesetContinuousVariableRecord and OutputAttributeContinuousVariableRecord) are both stored in the table VariableRecords. The columns of the VariableRecords table are defined using the OPENSTUDIO_ENUM macro as shown below:
Tables for all Records begin with the columns id and handle. The id column is an integer primary key which is used to uniquely identify objects within a single database. The handle column records an openstudio::UUID which can be used to uniquely identify objects across databases. Tables for all ObjectRecords additionally include the columns name, displayName, description, timestampCreate (time that the was created), timestampLast (time the object was last updated), and uuidLast (openstudio::UUID which uniquely identifies the last update to the object). After these columns, each table includes columns to store data for all derived types. Additional columns are required to store the type of each derived class, for example the column variableRecordType in the example above records whether the given row is a discrete or a continuous variable, and the column continuousVariableRecordType further designates whether a ContinuousVariableRecord is a ModelRulesetContinousVariableRecord or an OutputAttributeContinuousVariableRecord. If two derived class share the same data member, then those objects should save space by reusing the same column to store that data member. For instance, ModelRulesetContinousVariableRecord and OutputAttributeContinuousVariableRecord both use the field attributeName.
The following virtual methods are reimplemented for each class that derives from Record :
Two patterns have been established for serializing objects to ObjectRecords in the ProjectDatabase. The first pattern applies when the object is meant to be serialized entirely to the database. In this case, the object is paired with an ObjectRecord which serializes and deserializes the object fully from the ProjectDatabase. The object stores an openstudio::UUID which is used to determine if the database already contains a record for the object before a new record is created, this pattern is shown below. Objects serialized to the database have parent/child and resource relationships similar to the OpenStudio openstudio::model::ModelObjects. Adding an object to the database will add the object and ensure that all of its resources exist. Removing an object from the database will remove all children but will not remove resources. A RemoveUndo object is returned by ProjectDatabase::removeRecord, this object records all of the Records removed and can be used to commit or revert the remove operation.
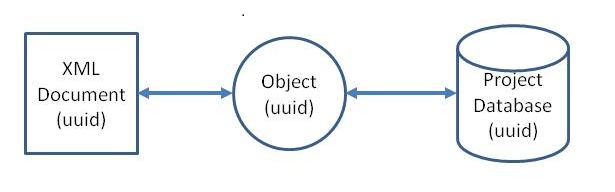
The second pattern applies to larger objects which are serialized to their own file format (e.g. openstudio::model::Model is saved to the OSM format). For these objects, the database does not need to fully serialize and deserialize the object, it only needs to maintain a reference to the serialized file on disk as well as information about the timestamp of the file and a checksum which can verify that the file has not changed since the Record was last updated. FileReferenceRecords , which serialize openstudio::FileReference (see utilities/core/FileReference.hpp), are used for this purpose. In most circumstances, a FileReferenceRecord will be a child of another record that knows/specifies that file's type and purpose. openstudio::model::Components are a notable exception, as FileReferenceRecord includes a specialized constructor and getter for this file/object type.
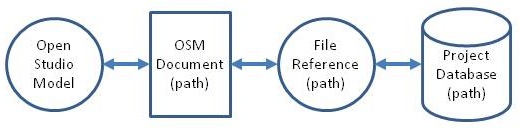
To ensure data consistency, ProjectDatabase objects must ensure that duplicate Records, that is, multiple Record objects that represent the same row in the database, cannot exist. The ProjectDatabase class does this by maintaining maps of object handles to new, clean, dirty, and removed Records . When adding, retrieving, or removing Records , the ProjectDatabase first checks if the Record already exists in one of these maps. If the Record is already in a map, then a new wrapper pointing to the existing implementation object is returned. If the Record is in a map, then a new implementation object is constructed and placed in the appropriate map. The problem with this solution is that SQL queries cannot be executed on objects loaded in these maps. Therefore, each operation that changes a Record is immediately saved in the database (including inserts and removes). The last saved state of the Record is stored as member variables in the Record to support reverting later, if the ProjectDatabase is not saved before its destructor is called. A RemoveUndo struct is used to undo removals of Records. This synchronization scheme is shown below:
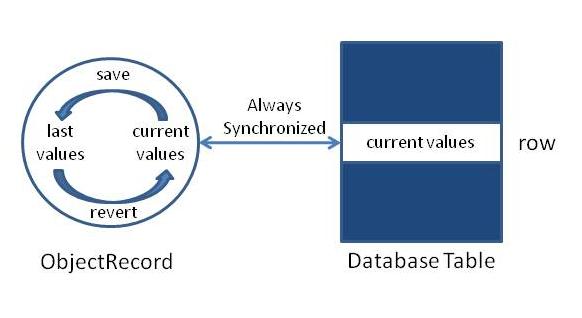
A side effect of this synchronization strategy is that operations which add, remove, or modify Records can take a long time, as they each require database writes. To avoid this, it is best to group add, remove, or modify statements within a transaction. Transactions are started using ProjectDatabase::startTransaction and saved using ProjectDatabase::commitTransaction. It is good practice to ensure that a transaction was actually started before trying to commit it:
A "gotcha" condition in this scheme is that queries no longer work on removed Records . Consider the following example: